Hypermedia seems not to be a popular option between API designers these days. On the other hand REST (or RESTful) API design is supposed to be the orthodoxy in API design and implementation.
This is not a surprise since REST, by simple abuse of the term, has become just a concept vaguely related to the use of ‘resources’ and a conventional mapping CRUD operations to HTTP methods.
But REST should be much more than that. Fielding’s thesis was an attempt of systematically describe the network architecture of the web built on a few key components (HTTP, URI, HTML). The meaning of architecture in REST is just a process of imposing constraints over the many possible ways of building distributed network systems.
Each of these constraints limit the way we can build the system, but at the same time, they make the final result more reliable, extensible, decoupled and able to scale. On the other hand, these same constraints can have a negative impact in other aspects, like raw performance. They are conscious trade-offs.
When building RESTful APIs these days, most of the problems come from the lack of reliability, fragility, coupling and the lack of scalability.These are the very same problems that REST architectural principles should help us to avoid.
There’s something wrong in our RESTful APIs.
A few months after the first web server was bootstrapped by Tim Berners Lee at CERN, the web was already composed of distributed servers linking information between multiple organisations. A couple of implementations of a generic client for the web were already being written. Both things are still impossible to achieve in the web of data APIs.
If we look again at the components of the web, HTTP is the only one we truly embrace. URI and HTML (or a version of HTML for data), and their combined use as hypermedia are lacking in most APIs.
This post tries to explore how hypermedia can be used in API design to fix some of the issues we have mentioned before: fragility, coupling and lack of scalability.
Instead of just discussing abstract notions and enumerating technologies and standards, the approach will be slightly different. We’ll start with a fully RPC API, with almost no other constraints than using the HTTP protocol for data transport, and we will start adding REST constraints through different revisions, Trying to understand the trade-offs involved in each small change.
The toy API we will be improving is just another variation of a ‘Todos’ service, where users can register and create and edit lists of Todo notes.
I will use RAML to describe the API, but I could use Swagger/OpenAPI, Blueprints or any other API documentation format.
API Version 0: RPC
The initial version of the API is just a list of RPC operations invoked over the HTTP protocol.
| #%raml 1.0 | |
| title: Todos Service | |
| baseUri: http://todosapp.com/api/version_0 | |
| mediaType: application/json | |
| /usersServiceCreate: | |
| description: Creates a users | |
| post: | |
| body: | |
| properties: | |
| email: string | |
| name: string | |
| response: | |
| body: | |
| properties: | |
| id: string | |
| /usersServiceList: | |
| description: Lists all Users | |
| post: | |
| response: | |
| body: | |
| type: array: | |
| items: | |
| properties: | |
| id: string | |
| email: string | |
| name: string | |
| /usersServiceDelete: | |
| description: Creates a users | |
| post: | |
| body: | |
| properties: | |
| id: string | |
| /todosServiceCreate: | |
| description: Creates Todos for a user | |
| post: | |
| body: | |
| properties: | |
| user_id: string | |
| todos: | |
| type: array | |
| items: | |
| properties: | |
| title: string | |
| description: string | |
| response: | |
| body: | |
| properties: | |
| id: string | |
| /todosServiceList: | |
| description: Lists all Todos | |
| post: | |
| response: | |
| body: | |
| type: array | |
| items: | |
| properties: | |
| id: string | |
| user_id: string | |
| title: string | |
| description: string | |
| /todosServiceDelete: | |
| description: Deletes todos | |
| post: | |
| body: | |
| id: string[] |
There are only two REST restrictions in this design:
- Client/server architecture: There’s a clear separation between the client side and server side of the service with a well defined boundary between them and clear separation of concerns
- Sateless architecture: all requests to the API include all the information required for the service to process the request. There are no dependencies between requests that can be issued in any particular order. Session state is kept in the client.
The API uses the HTTP protocol just as a transport layer for the invocation of remote functions in the server. The semantics of HTTP are ignored, all requests are bound to POST HTTP requests. It doesn’t take advantage of any of the features of the protocol, like caching headers, HTTP is just a convenient mechanism to invoke remote functions.
Understanding this version of the API requires reading the textual description of the operation and examining the payloads of requests and responses. The API describes a private communication protocol.
Coupling between clients and servers is also high. Client code must be tailored to match the description of the API endpoints. Any change in the service interface will break the client and it’s impossible to rely on any kind of client library other than basic HTTP library support.
On the other hand the removal of some of the REST constraints also has benefits. For example, since we are not imposing the notion of resources, we can save some requests to the server just by introducing end-points that accept arrays of identifiers to operate over sets of entities in the server side. It might be also possible to change the transport layer easily without changing the client code, just replacing the basic HTTP functionality by some other transport protocol. One example of this kind of API is Dropbox HTTP API.
API Version 1: Resources
The main change we are going to make in this version of the API is to add one of the main REST architectural elements: the notion of resource and resource representations.
If we just look at the version 0 of the API, we can see how different operations in the API rely on identifiers being received or returned by the operations endpoints. These identifiers designate entities in the service that operations in the API manipulate: users and todos.
If we assigned an identifier, a URI, to each of these entities we can consider them resources from a REST point of view. Resources are not to be confused with the actual state they are in. We can have resources for values that don’t exist yet, we can have multiple resources pointing to the same state, we can have resources whose state don’t change in time, and resources whose value changes constantly in time. The only important thing is that the semantics of the resource should not change, for example, the resource identified by http://todosapp.com/api/version_1/users/latest should always point to the latest user created in the system.
When we use the HTTP protocol to dereference a HTTP URI and retrieve the state associated to the resource the URI identifies, what we obtain is a representation of that state. This representation is fully transferred from the server to the client and it includes data and meta-data and can have multiple formats.
Clients need to select the most convenient representation for a resource among the representations available in the server using a mechanism known as content negotiation, involving the exchange of HTTP protocol headers containing media types.
Finally, in order to define how resources can be manipulated using the HTTP protocol, REST imposes another architectural constraint in our API: the uniform interface.
This interface defines the contract between client and servers and it is based in the semantics of the HTTP protocol. It includes a small set of methods that define how resources can be created, read, updated and deleted (CRUD).
In this new version of the API we will use these architectural elements and constraints to rewrite our API:
- We will group our entities in 4 main resource types: collection of users, individual users, collection of todos and individual todos
- Different representations for the resources: JSON and XML are introduced
- We map the CRUD functionality offered by the functions exposed by the API version 0 and we map them to the right HTTP methods
The outcome is a API similar to most RESTful APIs built nowadays, for example Twitter’s REST API
| #%RAML 1.0 | |
| title: Todos Service | |
| baseUri: http://todosapp.com/api/version_1 | |
| mediaType: [ application/json, application/xml ] | |
| types: | |
| User: | |
| properties: | |
| id: string | |
| email: string | |
| name: string | |
| Todo: | |
| properties: | |
| id: string | |
| title: string | |
| description: string | |
| /users: | |
| get: | |
| description: Gets all the users in the service | |
| responses: | |
| 200: | |
| body: User[] | |
| post: | |
| description: Creates a new user | |
| body: | |
| properties: | |
| email: string | |
| name: string | |
| password: string | |
| responses: | |
| 201: | |
| headers: | |
| Location: | |
| type: string | |
| /users/{id}: | |
| get: | |
| description: Information about a single user of the service | |
| responses: | |
| 200: | |
| body: User | |
| delete: | |
| description: Deletes a user from the service | |
| /users/{id}/todos: | |
| get: | |
| description: Lists all the Todos created by a user | |
| responses: | |
| 200: | |
| body: Todo[] | |
| post: | |
| description: Creates a new Todo for a user | |
| body: | |
| properties: | |
| title: string | |
| description: string | |
| responses: | |
| 201: | |
| headers: | |
| Location: | |
| type: string | |
| /users/{id}/todos/{todo_id}: | |
| get: | |
| description: Information about a single Todo for a user | |
| responses: | |
| 200: | |
| body: Todo | |
| delete: | |
| description: Deletes a Todo for a User from the service |
One of the trade-offs we have introduced with the addition of resources and the HTTP uniform interface is that achieving certain functionality might involve a bigger number of HTTP requests.
A partial solution to this problem can be found in another additional architectural constraints introduced by REST: cacheability.
Since the API respects the semantics of the HTTP protocol, the caching features built in HTTP can be used to reduce the number of requests required to retrieve the information available in the service. Caching in HTTP is based in a number of headers: Cache-control, Expires, Etags, that can be used by clients but also by any other intermediate HTTP connectors, like proxys, to avoid new requests for resources whose state can be inferred to be valid.
Another problem with this version of the API is that clients still need to know in advance the identifiers for the resources exposed through the HTTP interface. Relationships between resources are only implicitly present in the structure of the URIs. Clients need to know these identifiers and relations in advance and any change in these identifiers or in the structure of the resources will break the client logic.
However, the adoption of HTTP uniform interface can improve the support for re-usable libraries in clients. For example, if certain conventions in the way URIs for the resources are constructed, generic ‘REST’ libraries like Rails ActiveResource can be used.
API Version 2: Hyperlinks
In this revision of the API we are going to explore a solution to the coupling between client and servers we detected in version 1 of the API. We’ll address the problem introducing a form of hypermedia: http hyperlinks.
In version 1 of the API clients need to know in advance the URIs of the resources in the API. Moreover, they need to compute URIs dynamically from hard-coded templates extracting resource string identifiers from the representation retrieved from other resources. We’ll remove these requirements adding links inside the resource representations.
Hypermedia can be defined as control information that is embedded in data, in our case in the representation of resources. Through hypermedia, the server bundles together with the data the mechanism that clients can use to request that the server perform a certain operation on a resource. Thanks to hypermedia, the interface to the information can be packaged with the information and stored away from the server.
One kind of hypermedia are hyperlinks. They encode a relation between resources identified by URIs. Following a link, a client can retrieve a representation of the resource through the HTTP uniform interface, without any need of documentation or previous knowledge of the resource URI.
We will introduce links into our API using properties marked with a special suffix _url. Clients will need to understand the combination of these specially marked properties and string value they have assigned as links to the related resources.
An example of this kind of APIs with hyperlinks introduced in an ad-hoc way into resource payloads is Github API.
| #%RAML 1.0 | |
| title: Todos Service | |
| baseUri: http://todosapp.com/api/version_2 | |
| mediaType: [ application/json, application/xml ] | |
| types: | |
| User: | |
| properties: | |
| id: string | |
| email: string | |
| name: string | |
| self_url: string | |
| todos_url: string | |
| Todo: | |
| properties: | |
| id: string | |
| title: string | |
| description: string | |
| self_url: string | |
| user_url: string | |
| # ... |
Just adding links to the payload improves the reliability of the API and decouples clients from servers. Structure of URIs can change as long as the semantics for the link properties remain the same. If that is the case, client code does not need to change, we just need to find the right property and follow the link to retrieve the resource.
However, one of the problems with this solution is the use of JSON to encode the representation of resources. JSON doesn’t have syntactical support for links, we can only encode them as JSON strings in the payload. Clients are still coupled with the server because it is impossible for them to discover links in the representation. Clients written to take advantage of links will only work for this particular API and if the property introducing the link changes, even those clients will break.
API Version 3: Data Graph
In the previous version of this API we have shown the benefits of adding hyperlinks to the representation of resources. However we found that we are limited in our capacity of working with these links when encoded as JSON because this format does not support hyperlinks. XML, the other representation we support, has a similar problem, but being an extensible data format, links can be introduced in a standard way using XLink.
In order to deal with hyperlinks in JSON we need to augmentate its syntax. Since JSON doesn’t provide extensibility features we will need a superset of the format identified by a completely new media type.
Many options have been proposed to introduce hypermedia on top of JSON, HAL or Siren are just two examples.
In this version of the API we will use for this purpose JSON-LD.
JSON-LD is a W3C recommendation, with a minimalistic syntax, good support for tools and increasing adoption.
Links in JSON-Ld are URI strings wrapped into a { "@id": URI } JSON object. To avoid ambiguity in the properties used in JSON objects, JSON-LD properties must also be URIs. To provide a simple way to transform properties strings into URIs, JSON-LD introduces a "@context" property where a "@vocab" prefix can be declared to be used by all properties in the object.
In the following revision of the API spec we will introduce a couple of additional types to describe JSON-LD syntax:
| #%RAML 1.0 | |
| title: Todos Service | |
| baseUri: http://todosapp.com/api/version_3 | |
| mediaType: [ application/ld+json, application/json, application/xml ] | |
| types: | |
| URI: string | |
| Link: | |
| properties: | |
| @id: URI | |
| Context: | |
| properties: | |
| @vocab: URI | |
| User: | |
| properties: | |
| @context: Context | |
| @id: URI | |
| email: string | |
| name: string | |
| todos: Link | |
| Todo: | |
| properties: | |
| @context: Context | |
| @id: URI | |
| title: string | |
| description: string | |
| user: Link | |
| # ... |
In this version of the spec we have introduced the Link and Context types and the URI alias to support JSON-LD syntax. We have also replaced the old id identifiers by JSON-LD @id URIs based identifiers.
When requesting a particular resource from the API:
| curl -X GET -H "Accept: application/ld+json" http://todosapp.com/api/version_3/users/1/todos/1 |
The JSON-LD representation returned by the server looks like:
| { | |
| "@context": { "@vocab": "http://todosapp.com/api/vocab#" }, | |
| "@id": "http://todosapp.com/api/version_3/users/1/todos/1", | |
| "title": "Test", | |
| "description": "Test TODO", | |
| "user": { "@id": "http://todosapp.com/api/version_3/users/1" } | |
| } |
The same representation could be expressed in a different way omitting the @context property like:
| { | |
| "@id": "http://todosapp.com/api/version_3/users/1/todos/1", | |
| "http://todosapp.com/api/vocab#title": "Test", | |
| "http://todosapp.com/api/vocab#description": "Test TODO", | |
| "http://todosapp.com/api/vocab#user": { "@id": "http://todosapp.com/api/version_3/users/1" } | |
| } |
The payload of the JSON-LD representation of this resource can be understood as a data graph where the properties are links between resources identified with URIs and literal properties:
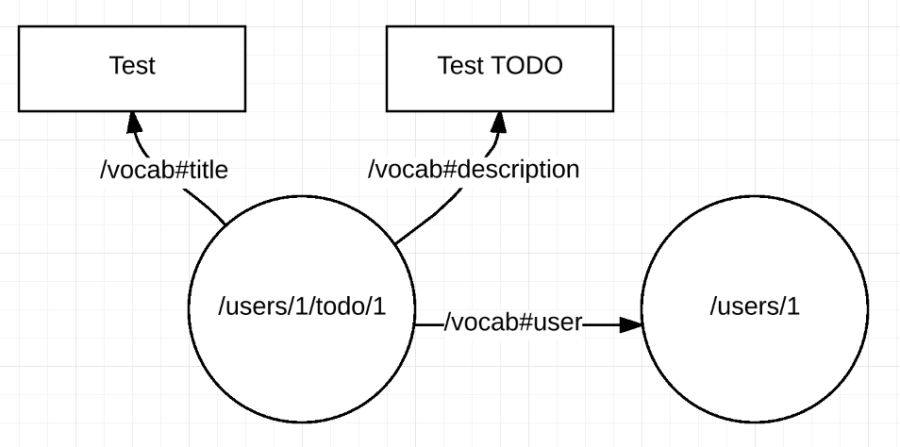
The same graph can be serialised as sequence of assertions SUBJECT PREDICATE OBJECT:
This capacity of interpreting a JSON-LD document as a data graph is a powerful feature, specially when dealing with hyperlinks between resources.
In a REST API, state is transferred from the service to clients. Relations between resources are denoted by links in the representation of resources that can be traversed using the HTTP protocol. For example we could follow the http://todosapp.com/api/vocab#user property contained in the previous representation:
| curl -X GET -H "Accept: application/ld+json" http://todosapp.com/api/version_3/users/1 |
To retrieve the JSON-LD representation:
| { | |
| "@context": { "@vocab": "http://todosapp.com/api/vocab#" }, | |
| "@id": "http://todosapp.com/api/users/1", | |
| "name": "John Doo", | |
| "email": "john.doo@test.com", | |
| "todos": { "@id": "http://todosapp.com/api/users/1/todos" } | |
| } |
This JSON-LD document can also be interpreted as a data graph:
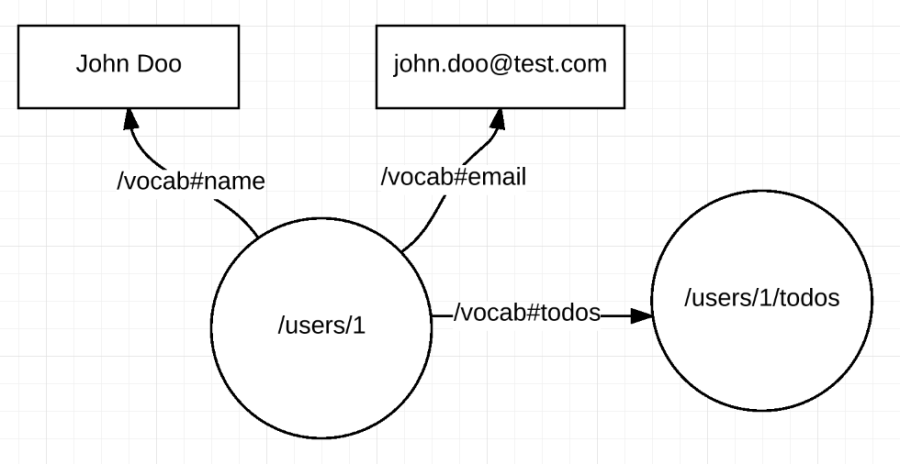
Both graphs can be merged in the client just appending the assertions:
To obtained the combined data graph:

We have been able to re-construct in the client a graph of data distributed across multiple HTTP resources just merging the underlying JSON-LD data model.
This distributed data graph model is specified in the RDF W3C recommendation and it opens multiple possibilities for clients.
For example, we could query the local data graph using the SPARQL and client library like RDFStore-JS.
| PREFIX todos: <http://todosapp.com/api/vocab#> | |
| SELECT ?name (COUNT(?todo) AS ?todos) | |
| WHERE { | |
| ?user todos:name ?name . | |
| ?todo todos:user ?user | |
| } | |
| GROUP BY ?name |
To obtain the following results:
| | ?name | ?todos | | |
| |-----------|----------| | |
| | John Doo | 1 | | |
| |-----------|----------| |
This ability to merge and query distributed information exposed as HTTP resources in a standard data format, is the foundation to build generic API clients completely decoupled from the server. It can be the core of a hypothetical generic client for APIs, equivalent to a web browser for the web of documents.
API Version 3.1: URIs
In version 3 of the API we have seen how to embed hyperlinks in the representations of resources. In this revision we are going to address a problem related to the way we are building identifiers for these resources.
The notion of a URI has evolved since the original conception of the web.
At the beginning, in a web of documents, URIs were just identifiers for these documents (or more technically, information resources), specifying their location in the network and the network protocol that should be used to retrieve them.
But URIs cannot only be used to locate documents, they can be used to identify resources in the REST sense. REST resources are concepts (technically non information resources) that cannot be transmitted using the HTTP protocol. Resources can mean anything, from a person to Mount Everest, the only condition is that resources need to be identified by URIs.
So the question is: what should a server do when a client issues a HTTP GET request for a URI identifying a non information resource like Mount Everest?
This problem is known as ‘HTTP Range 14’ after the issue were it was first raised.
From a REST point of view the solution is clear, the resource cannot be transmitted, but a representation for the resource agreed between client and server through content negotiation can be transmitted. The question is if URIs for the resource and the representation should be the same.
Different solutions have been proposed, one is to use HTTP re-directions to send clients from the resource to the representation of the resource.
Our favored solution is to use two different kind of URIs:
- Hash URIs like
http://todosapp.com/api/users/1/todos/1#selfused for naming resources and other ‘non information resources’ - URLs a subset of URIs that can be used as locators, like
http://todosapp.com/api/users/1/todos/1, for ‘information resources’
The interesting thing about this solution is that it offers a mechanism to automatically relate both URIs.
Hash URIs cannot be directly dereferenced by a HTTP client. If a client tries to dereference a hash URI the fragment is removed and the remaining URI, a potential URL, is sent in the request.
We can use this fact to distinguish the resource http://todosapp.com/api/users/1/todos/1#self from the JSON-LD document where the resource is described http://todosapp.com/api/users/1/todos/1. Moreover, the hash URI will appear inside the data graph encoded in the document.

We will change our API so every resource will be identified using a hash URI. An example representation for a resource will look like:
| [ | |
| { | |
| "@context": { "@vocab": "http://todosapp.com/api/vocab#" }, | |
| "@id": "http://todosapp.com/api/users/1/todos/1#self", | |
| "title": "Test", | |
| "description": "Test TODO", | |
| "user": { "@id": "http://todosapp.com/api/users/1#self" } | |
| } | |
| ] |
An example of an API addressing the HTTP Range 14 issue is dbpedia. If we try to request the Mount Everest resource (http://dbpedia.org/resource/Mount_Everest) in dbpedia with a JSON-LD representation (or with a web browser) we will be redirected to the right URL for the resource representation:
| $ curl -iv -H "Accept: application/ld+json" http://dbpedia.org/resource/Mount_Everest | |
| * Trying 194.109.129.58... | |
| * Connected to dbpedia.org (194.109.129.58) port 80 (#0) | |
| > GET /resource/Mount_Everest HTTP/1.1 | |
| > Host: dbpedia.org | |
| > User-Agent: curl/7.43.0 | |
| > Accept: application/ld+json | |
| > | |
| < HTTP/1.1 303 See Other | |
| HTTP/1.1 303 See Other | |
| < Location: http://dbpedia.org/data/Mount_Everest.jsonld | |
| Location: http://dbpedia.org/data/Mount_Everest.jsonld | |
| # ... | |
| < | |
| * Connection #0 to host dbpedia.org left intact | |
| $ curl -iv -H "Accept: text/html" http://dbpedia.org/resource/Mount_Everest | |
| * Trying 194.109.129.58... | |
| * Connected to dbpedia.org (194.109.129.58) port 80 (#0) | |
| > GET /resource/Mount_Everest HTTP/1.1 | |
| > Host: dbpedia.org | |
| > User-Agent: curl/7.43.0 | |
| > Accept: text/html | |
| > | |
| < HTTP/1.1 303 See Other | |
| HTTP/1.1 303 See Other | |
| < Location: http://dbpedia.org/page/Mount_Everest | |
| Location: http://dbpedia.org/page/Mount_Everest | |
| # ... | |
| < | |
| * Connection #0 to host dbpedia.org left intact |
API Version 3.2: Collections
In this revision of the API we are going to introduce the concept of collection resources.
Up to this we have paid attention to individual resources, Users and Todos. We have also introduced hash URIs to identify them property and distinguish them from their representations. But if we look at URIs like http://todosapp.com/api/version_3_1/users they are being treated as URLs pointing to a JSON-LD document containing a data graph that can be fully partitioned in as many sub-graphs as user resources have been created in the service. The problem is that these collections of resources are not resources themselves. They don’t have a hash URI identifying them, they will never appear as subject resource in the client data graph.
Furthermore, since they are not resources, we cannot describe them. We cannot, for instance, assert that the collection of users is paginated or at what time the last user was created.
To solve this problem, we will introduce a Collection type of resource, with its own hash URI and a property members pointing to the URIs of the contained resources.
| #%RAML 1.0 | |
| title: Todos Service | |
| baseUri: http://todosapp.com/api/version_3_2 | |
| mediaType: [ application/ld+json, application/json, application/xml ] | |
| types: | |
| URI: string | |
| Link: | |
| properties: | |
| @id: URI | |
| Context: | |
| properties: | |
| @vocab: URI | |
| User: | |
| properties: | |
| @context: Context | |
| @id: URI | |
| email: string | |
| name: string | |
| todos: Link | |
| Todo: | |
| properties: | |
| @context: Context | |
| @id: URI | |
| title: string | |
| description: string | |
| user: Link | |
| Collection: | |
| properties: | |
| @context: Context | |
| @id: URI | |
| members: Link[] | |
| /users: | |
| get: | |
| description: Gets all the users in the service | |
| responses: | |
| 200: | |
| body: Collection | |
| post: | |
| description: Creates a new user | |
| body: | |
| properties: | |
| email: string | |
| name: string | |
| password: string | |
| responses: | |
| 201: | |
| headers: | |
| Location: | |
| type: string | |
| /users/{id}: | |
| get: | |
| description: Information about a single user of the service | |
| responses: | |
| 200: | |
| body: User | |
| delete: | |
| description: Deletes a user from the service | |
| /users/{id}/todos: | |
| get: | |
| description: Lists all the Todos created by a user | |
| responses: | |
| 200: | |
| body: Collection | |
| post: | |
| description: Creates a new Todo for a user | |
| body: | |
| properties: | |
| title: string | |
| description: string | |
| responses: | |
| 201: | |
| headers: | |
| Location: | |
| type: string | |
| /users/{id}/todos/{todo_id}: | |
| get: | |
| description: Information about a single Todo for a user | |
| responses: | |
| 200: | |
| body: Todo | |
| delete: | |
| description: Deletes a Todo for a User from the service |
If we now follow a link leading to a Collection resource in our data graph we will obtain the following representation:
| { | |
| "@context": { "@vocab": "http://todosapp.com/api/vocab#" }, | |
| "@id": "http://todosapp.com/api/users/1/todos#self", | |
| "members": [ | |
| { "@id": "http://todosapp.com/api/users/1/todos/1#self" }, | |
| { "@id": "http://todosapp.com/api/users/1/todos/2#self" } | |
| ] | |
| } |
And we could add that information to our data graph to obtain a more connected graph:

Another design decision we have taken is to reduce the properties in the members of the collection resource to include just the link to the member resource. That’s the only requirement from the hyper-media point of view, but that also supposes that we need to issue a new HTTP request if we want to obtain any other information about the member resource.
The opposite solution would be to embed the full member resource data graph in the collection representation, minimising in this way the number of required requests to retrieve the information but increasing the size of the request payload. Intermediate solutions, where some properties are in-lined are also possible. The designer of the API must decide what is the right granularity for her use case.
API Version 3.3: Entry Point
In version 3.2 of the API we have connected our data graph of resources introducing Collection resources. However there’s still a resource we cannot reach the collection of all the users http://todosapp.com/api/version_3_2/users#self. We still need to document that ‘end-point’ in our RAML API spec for a client capable of following hyper-links to be able to explore our API.
In fact, that’s the only URI that we need to document, since all the resources in the API include hyper-links in their representation and they are documented in the description of the resource types.
One of the goals of REST design is that a single URI should be enough for a client to consume the API. We will make that idea explicit introducing a new type of resource an EntryPoint resource type with a single resource, the URI that will be the entry-point for our API. The entry-point itself will only include a link to the collection of all users.
We will also remove all the other end-points in our RAML specification to leave only the reference to the entry-point URI.
| #%RAML 1.0 | |
| title: Todos Service | |
| baseUri: http://todosapp.com/api/version_3_3 | |
| mediaType: [ application/ld+json, application/json, application/xml ] | |
| types: | |
| URI: string | |
| Link: | |
| properties: | |
| @id: URI | |
| Context: | |
| properties: | |
| @vocab: URI | |
| EntryPoint: | |
| @context: Context | |
| @id: URI | |
| users: Link | |
| User: | |
| properties: | |
| @context: Context | |
| @id: URI | |
| email: string | |
| name: string | |
| todos: Link | |
| Todo: | |
| properties: | |
| @context: Context | |
| @id: URI | |
| title: string | |
| description: string | |
| user: Link | |
| Collection: | |
| properties: | |
| @context: Context | |
| @id: URI | |
| members: Link[] | |
| /: | |
| get: | |
| description: Entry point for the application | |
| responses: | |
| 200: | |
| body: EntryPoint |
An example of API with entry-point is again Github’s HTTP API where it is denominated ‘Root Endpoint’.
API Version 4: Read-Write API
In the different revisions 3.X of the API we have built a quite sophisticated REST API with support for hyperlinks.
The main problem with the resulting API is that it is read-only. It would be equivalent to a version of the web working with HTML supporting only ‘<a></a>’ tags and without support for ‘<form></form>’ elements.
To define a read-write version of the API, we need to support richer forms of hypermedia encoding control information for the whole HTTP uniform interface.
JSON-LD only provides syntax to encode hyperlinks in the JSON-LD document, but this is not a problem, since we can insert the required hypermedia controls in the data graph, encoding them in the same way we encode the data.
For example, let’s create a new type in our RAML specification called Operation and let’s allow Links to have an associated array of operations.
We will also introduce two ‘template’ types UserTemplate and TodoTemplate to document the shape of the payload required by the service to create a new User and Todo respectively:
| #%RAML 1.0 | |
| title: Todos Service | |
| baseUri: http://todosapp.com/api/version_4 | |
| mediaType: [ application/ld+json, application/json, application/xml ] | |
| types: | |
| URI: string | |
| Type: string | |
| Operation: | |
| method: | |
| enum: [ GET, POST, PUT, DELETE, PATCH, HEAD, OPTIONS ] | |
| expects: Type | |
| returns: Type | |
| Link: | |
| properties: | |
| @id: URI | |
| operations: Operation[] | |
| Context: | |
| properties: | |
| @vocab: URI | |
| EntryPoint: | |
| @context: Context | |
| @id: URI | |
| users: Link | |
| UserTemplate: | |
| properties: | |
| name?: string | |
| email: string | |
| User: | |
| properties: | |
| @context: Context | |
| @id: URI | |
| email: string | |
| name: string | |
| todos: Link | |
| Todo: | |
| properties: | |
| @context: Context | |
| @id: URI | |
| title: string | |
| description: string | |
| user: Link | |
| TodoTemplate: | |
| properties: | |
| title: string | |
| description?: string | |
| Collection: | |
| properties: | |
| @context: Context | |
| @id: URI | |
| members: Link[] | |
| /: | |
| get: | |
| description: Entry point for the application | |
| responses: | |
| 200: | |
| body: EntryPoint |
Now, if we request any resource in the API we will retrieve a much richer set of hypermedia controls with enough control information to consume the whole HTTP uniform interface.
| { | |
| "@context": { "@vocab": "http://todosapp.com/api/vocab#" }, | |
| "@id": "http://todosapp.com/api/version_4/users/1#self", | |
| "name": "John Doo", | |
| "email": "john.doo@test.com", | |
| "todos": { | |
| "@id": "http://todosapp.com/api/version_4/todos#self", | |
| "operations": [ | |
| { | |
| "method": "GET", | |
| "returns": "Collection" | |
| }, | |
| { | |
| "method": "POST", | |
| "expects": "TodoTemplate", | |
| "returns": "Todo" | |
| } | |
| ] | |
| } |
Our data graph has also been enriched with additional nodes for the hyper-media controls. The control nodes are in this particular implementation anonymous, blank nodes in the graph, with URIs that cannot be dereferenced outside the local graph.

Consuming this version of the API, a generic hypermedia client could query the data graph encoded in the resource representation using SPARQL to discover the hypermedia controls embedded in the resource representation:
| SELECT ?resource ?method | |
| WHERE { | |
| ?resource <http://todosapp.com/api/vocab#oerations> ?operation . | |
| ?operation <http://todosapp.com/api/vocab#method> ?method . | |
| } | |
| ORDER BY(?resource) |
To obtain the results:
| | ?resource | ?method | | |
| |-------------------------------------------------|------------| | |
| | <http://todosapp.com/api/version_4/todos#self> | GET | | |
| | <http://todosapp.com/api/version_4/todos#self> | POST | | |
| |-------------------------------------------------|------------| |
API Version 5: Meta-data
Two of the major goals of REST are robustness and extensibility: the ability to gradually deploy changes in the architecture.
This is granted by the extensible elements of the HTTP protocol, like versioning or headers and by separating the parsing of the messages from their semantic. HTTP also constrains these messages to be self-descriptive by the inclusion of meta-data in the resource representation.
In the web of documents the notion of self-descriptive messages is usually equated to assigning media types to the messages. This is usually just a way of describing the format of the message for the client to be able to select a supported representation.
When we are working with APIs, meta-data we should also try to make our messages, the returned representation of a resource, to be self-descriptive, introducing as much meta-data as it is required for a client to automatically process the representation.
In a narrow sense this conception of meta-data matches the notion of schema: “the payload is a map with two properties (name and email) and types ‘string’ and ‘string'”. It can also mean the notion of a ‘type’ for the resource: “User”, “Todo”. Ultimately should mean the semantics of the resource: “name and email of the persons using our service”.
In the version 4 of the API these meta-data are encoded in our RAML specification. The main problem with this approach is that this information is not encoded in the resource representations at all. So far, it lives in a document completely outside of the API and it is not available for API clients.
In this version of the API we are going to make our API representation self-descriptive using hypermedia. First, we are going to introduce a property resource_type designating the type of resource for the different resources. Secondly, we will add a hyper-link linking to the RAML description of the API:
| #%RAML 1.0 | |
| title: Todos Service | |
| baseUri: http://todosapp.com/api/version_5 | |
| mediaType: [ application/ld+json, application/json, application/xml ] | |
| types: | |
| URI: string | |
| Type: string | |
| Operation: | |
| method: | |
| enum: [ GET, POST, PUT, DELETE, PATCH, HEAD, OPTIONS ] | |
| expects: Type | |
| returns: Type | |
| Link: | |
| properties: | |
| @id: URI | |
| operations: Operation[] | |
| Context: | |
| properties: | |
| @vocab: URI | |
| EntryPoint: | |
| @context: Context | |
| @id: URI | |
| described_by: Link | |
| resource_type: Type | |
| users: Link | |
| UserTemplate: | |
| properties: | |
| name: string | |
| email?: string | |
| User: | |
| properties: | |
| @context: Context | |
| @id: URI | |
| described_by: Link | |
| resource_type: Type | |
| email: string | |
| name: string | |
| todos: Link | |
| Todo: | |
| properties: | |
| @context: Context | |
| @id: URI | |
| described_by: Link | |
| resource_type: Type | |
| title: string | |
| description: string | |
| user: Link | |
| TodoTemplate: | |
| properties: | |
| title: string | |
| description?: string | |
| Collection: | |
| properties: | |
| @context: Context | |
| @id: URI | |
| described_by: Link | |
| resource_type: Type | |
| members: Link[] | |
| /: | |
| get: | |
| description: Entry point for the application | |
| responses: | |
| 200: | |
| body: EntryPoint |
Now if we request any resource of the API, the payload we will include the additional meta-data:
| { | |
| "@context": { "@vocab": "http://todosapp.com/api/vocab#" }, | |
| "@id": "http://todosapp.com/api/version_5/users/1#self", | |
| "resource_type": "User", | |
| "name": "John Doo", | |
| "email": "john.doo@test.com", | |
| "described_by": { "@id": "http://todosapp.com/api/version_5/spec.raml" }, | |
| "todos": { | |
| "@id": "http://todosapp.com/api/version_4/todos#self", | |
| "operations": [ | |
| { | |
| "method": "GET", | |
| "returns": "Collection" | |
| }, | |
| { | |
| "method": "POST", | |
| "expects": "TodoTemplate", | |
| "returns": "Todo" | |
| } | |
| ] | |
| } |
And the additional nodes will be added to the resource data graph:
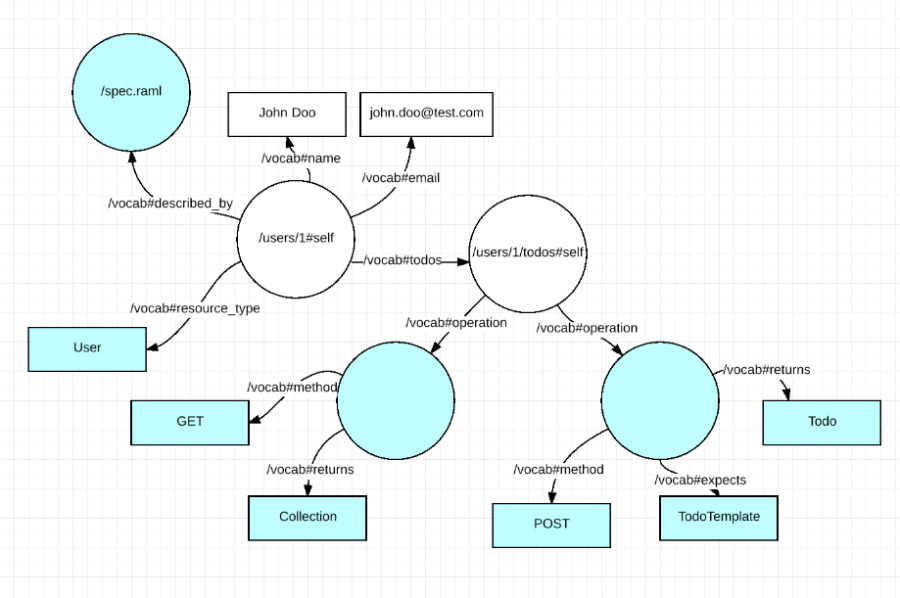
This solution has a number of shortcomings:
- Some meta-data is encoded as resources with URIs inside the data graph (like hyper-media controls) other is encoded as RAML in a document linked through a URL
- The connection is made by a plain string, the type name in the RAML document, it is impossible to link it using a hyper-link
- Clients need two different parsers, one for JSON-LD and another one for RAML
- The protocol to discover meta-data is completely private, the client needs to understand the
http://todosapp.com/api/vocab#described_byproperty - The size of the payloads keep on increasing with more meta-data
API Version 6: Self-descriptive API
A possible solution for the issues we have found in version 5 of the API, that is consistent with our design, is to move the meta-data from the representations to a different plane above the representations and link the meta-data to the resources using a hyper-link.
A possible implementation of this solution is to introduce a new resource type Class in the RAML specification. This type will encode the the information of the RAML spec itself. With this resource type defined, we can introduce another new resource of type ApiDocumentation exposing the RAML specification information as yet another resource in the API with its own URI.
| #%RAML 1.0 | |
| title: Todos Service | |
| baseUri: http://todosapp.com/api/version_6 | |
| mediaType: application/json+ld | |
| types: | |
| URI: string | |
| Operation: | |
| method: | |
| enum: [ GET, POST, PUT, DELETE, PATCH, HEAD, OPTIONS ] | |
| expects: Link | |
| returns: Link | |
| Link: | |
| properties: | |
| @id: URI | |
| operations: Operation[] | |
| Context: | |
| properties: | |
| @vocab: URI | |
| Class: | |
| @id: URI | |
| operations: Operation[] | |
| properties: | |
| @id: URI | |
| domain: URI | |
| range: URI | |
| links: Link[] | |
| Resource: | |
| @id: URI | |
| @type: URI | |
| ApiDocumentation: | |
| @id: URI | |
| @type: URI | |
| classes: Class[] | |
| entryPoint: URI | |
| /spec: | |
| get: | |
| description: API specification | |
| 200: | |
| body: ApiDocumentation | |
| /: | |
| get: | |
| description: Entry point for the application | |
| responses: | |
| 200: | |
| body: Resource |
Now, if we try to retrieve an API resource, we will obtain a much small data graph in the resource representation:
| { | |
| "@context": { "@vocab": "http://todosapp.com/api/vocab#" }, | |
| "@id": "http://todosapp.com/api/version_6/#self", | |
| "@type": "http://todosapp.com/api/version_6/spec#EntryPoint", | |
| "users_url": { "@id": "http://todosapp.com/api/version_6/users#self" } | |
| } |
The @type keyword in JSON-LD is a way of denoting the type for a typed node in the encoded data graph and it will be expanded to the URI http://www.w3.org/1999/02/22-rdf-syntax-ns#type. If the client now follows the provided @type link, all meta-data for the resource will be retrieved from the server.
It is important to note that types are no longer strings, they are URIs pointing to resources in the same way properties are, that’s the reason we can now connect them with hyperlinks
| curl -X GET "http://todosapp.com/api/version_6/spec#EntryPoint |
Both graphs, the data and meta-data graph can be merged into a single unified data-graph in the client that can be queried in the same way as in previous versions.

This distinction between two related ‘planes’ of information, one for data and one for meta-data, is what technically is known as the distinction between the Tbox for terminological box and the Abox for assertional box. From the logical point of view, the first component contains the conceptualisation of the system, the semantics of the data model, the second component contains the data, regarded as assertions over the concepts defined in the Tbox.
API Version 7: Generic Hypermedia API
In the previous version we have transformed the meta-data in our RAML API description into resources and we have exposed them using REST principles to describe the semantics of our API.
Both kind of resources are linked and conform a single data graph that can be discovered and explored by any client that understand the semantics of the control hypermedia.
At this point we no longer need the RAML document, the only thing we require is the URI of the single ‘EntryPoint’ resource.
The main problem of version 6 of the API is that the vocabulary used to describe hypermedia control information and the semantics of the resource types is private to our API.
In order to build a generic hypermedia API client, a truly generic API browser, we would need a standard way describing that information, a common vocabulary for hypermedia in APIs.
Fortunately, an effort to standarised such a vocabulary is currently underway in the W3C. It is called Hydra.
Hydra provides a rich vocabulary for describing hypermedia in APIs. The vocabulary we have used up to version 6 is just a sub-set of Hydra.
We could rewrite our ApiDocumentation class to use Hydra to describe the API so any generic Hydra browser could consume it:
| curl -X GET "http://todosapp.com/api/version_7/ |
| { | |
| "@context": { "@vocab": "http://todosapp.com/api/vocab#" }, | |
| "@id": "http://todosapp.com/api/version_7/#self", | |
| "@type": "http://todosapp.com/api/vocab#EntryPoint", | |
| "users_url": { "@id": "http://todosapp.com/api/version_7/users#self" } | |
| } |
| curl -X GET "http://todosapp.com/api/version_7/spec#EntryPoint |
| { | |
| "@context": { | |
| "hydra": "http://www.w3.org/ns/hydra/core#" | |
| }, | |
| "@id": "http://todosapp.com/api/vocab#self", | |
| "@type": "hydra:ApiDocumentation", | |
| "hydra:entryPoint": { "@id":"http://todosapp.com/api/version_7/#self" }, | |
| "hydra:supportedClass": [ | |
| { | |
| "@id": "http://todosapp.com/api/vocab#User", | |
| "@type": "hydra:Class", | |
| "hydra:supportedOperation": [ | |
| { | |
| "hydra:method": "GET", | |
| "hydra:returns": { "@id": "http://todosapp.com/api/vocab#User" } | |
| }, | |
| { | |
| "hydra:method": "DELETE" | |
| } | |
| ], | |
| "hydra:supportedProperty": [ | |
| { | |
| "hydra:property": { | |
| "@id": "http://todosapp.com/api/vocab#name", | |
| "rdfs:range": "xsd:string" | |
| }, | |
| "readonly": false, | |
| "required": false | |
| }, | |
| { | |
| "hydra:property": { | |
| "@id": "http://todosapp.com/api/vocab#email", | |
| "rdfs:range": "xsd:string" | |
| }, | |
| "readonly": false, | |
| "required": true | |
| }, | |
| { | |
| "hydra:property": { | |
| "@id": "http://todosapp.com/api/vocab#todos", | |
| "@type": "hydra:Link", | |
| "hydra:supportedOperation": [ | |
| { | |
| "hydra:method": "GET", | |
| "hydra:returns": { "@id": "hydra:Collection" } | |
| }, | |
| { | |
| "hydra:method": "POST", | |
| "hydra:expects": { "@id": "http://todosapp.com/api/vocab#Todo" }, | |
| "hydra:returns": { "@id": "http://todosapp.com/api/vocab#Todo" } | |
| }, | |
| ] | |
| } | |
| } | |
| ] | |
| }, | |
| { | |
| "@id": "http://todosapp.com/api/vocab#Todo", | |
| "@type": "hydra:Class", | |
| "hydra:supportedOperation": [ | |
| { | |
| "hydra:method": "GET", | |
| "hydra:returns": { "@id": "http://todosapp.com/api/vocab#Todo" } | |
| }, | |
| { | |
| "hydra:method": "DELETE" | |
| } | |
| ], | |
| "hydra:supportedProperty": [ | |
| { | |
| "hydra:property": { | |
| "@id": "http://todosapp.com/api/vocab#title", | |
| "rdfs:range": "xsd:string" | |
| }, | |
| "readonly": false, | |
| "required": true | |
| }, | |
| { | |
| "hydra:property": { | |
| "@id": "http://todosapp.com/api/vocab#description", | |
| "rdfs:range": "xsd:string" | |
| }, | |
| "readonly": false, | |
| "required": false | |
| }, | |
| { | |
| "hydra:property": { | |
| "@id": "http://todosapp.com/api/vocab#user", | |
| "@type": "hydra:Link", | |
| "hydra:supportedOperation": [ | |
| { | |
| "hydra:method": "GET", | |
| "hydra:returns": { "@id": "http://todosapp.com/api/vocab#User" } | |
| } | |
| ] | |
| } | |
| } | |
| ] | |
| }, | |
| { | |
| "@id": "http://todosapp.com/api/vocab#EntryPoint", | |
| "@type": "hydra:Class", | |
| "hydra:supportedOperation": [ | |
| { | |
| "hydra:method": "GET", | |
| "hydra:returns": { "@id": "http://todosapp.com/api/vocab#EntryPoint" } | |
| } | |
| ], | |
| "hydra:supportedProperty": [ | |
| { | |
| "hydra:property": { | |
| "@id": "http://todosapp.com/api/vocab#users_url", | |
| "@type": "hydra:Link", | |
| "hydra:supportedOperation": [ | |
| { | |
| "hydra:method": "GET", | |
| "hydra:returns": { "@id": "hydra:Collection" } | |
| }, | |
| { | |
| "hydra:method": "POST", | |
| "hydra:expects": { "@id": "http://todosapp.com/api/vocab#User" }, | |
| "hydra:returns": { "@id": "http://todosapp.com/api/vocab#User" } | |
| }, | |
| ] | |
| } | |
| } | |
| ] | |
| } | |
| ] | |
| } |
Additionally, we will introduce another discovery mechanism in our server, we will include a HTTP Link header as described in RFC5988 and prescribed in Hydra recommendation draft to make clients aware of the location of the meta-data graph:
| Link: <http://todosapp.com/api/vocab>; rel="http://www.w3.org/ns/hydra/core#apiDocumentation" |
Now we have a truly generic hyper-media enabled API.
This is just a starting point. Since we have support for the same powerful architecture that powers the web in our API, we can use it to change the way we address a number of problems in APIs: client identity, authentication, ACLs, validation, API integration and clients collaboration, all these problems could be solved in a truly de-centralised and scalable just relying in the support for hypermedia and meta-data this architecture for building APIs enable.

I wish you’d add URI Templates to the mix somewhere around version 3.x. Otherwise this is probably the most useful introduction to JSON-LD et al. that I’ve seen. Kudos!
This is great!
Is there a single github repo with this somewhere? I see the snippets, but not a running example that could be downloaded ? Maybe I missed a link?
one of the most valuable articles I have found about the topic. Epic .